")
En la era de la inteligencia artificial, la clasificación de documentos ha evolucionado significativamente. Los Modelos de Lenguaje Grande (LLMs) han emergido como una herramienta poderosa y flexible para esta tarea. Este artículo explora cómo utilizar LLMs para la clasificación avanzada de documentos, ofreciendo una alternativa dinámica y agnóstica a los servicios tradicionales de clasificación.
Clasificación con LLMs
El proceso de clasificación con LLMs implica extraer el contenido del documento (por ejemplo, usando pypdf) y agregarlo a un prompt junto con las posibles clasificaciones. Aquí hay un ejemplo básico de cómo estructurar la respuesta de clasificación usando instructor, ya que es sencillo de utilizar.:
from typing import Optional
from pydantic import BaseModel, Field
class ClassificationResponse(BaseModel):
name: str
confidence: Optional[int] = Field("From 1 to 10. 10 being the highest confidence")Este ejemplo básico te dará la mejor categorización y nivel de certeza. Si el nivel de confianza no es adecuado, puedes optar por usar otro modelo como una alternativa fácil y eficaz.

Mapeo de Tipos con Estructura de Contrato
Para mejorar la confianza en la clasificación, se puede incluir la estructura del contrato en el prompt. Esto es particularmente útil cuando la clasificación va seguida de una extracción de datos. Aquí hay un ejemplo de cómo agregar la estructura del contrato al prompt usando Pydantic:
def _add_classification_structure(self, contract: BaseModel) -> str:
content = ""
if contract:
content = "\tContract Structure:\n"
for name, field in contract.model_fields.items():
field_str = str(field)
field_type = field_str.split('=')[1].split(' ')[0]
required = 'required' in field_str
attributes = f"required={required}"
field_details = f"\t\tName: {name}, Type: {field_type}, Attributes: {attributes}"
content += field_details + "\n"
return content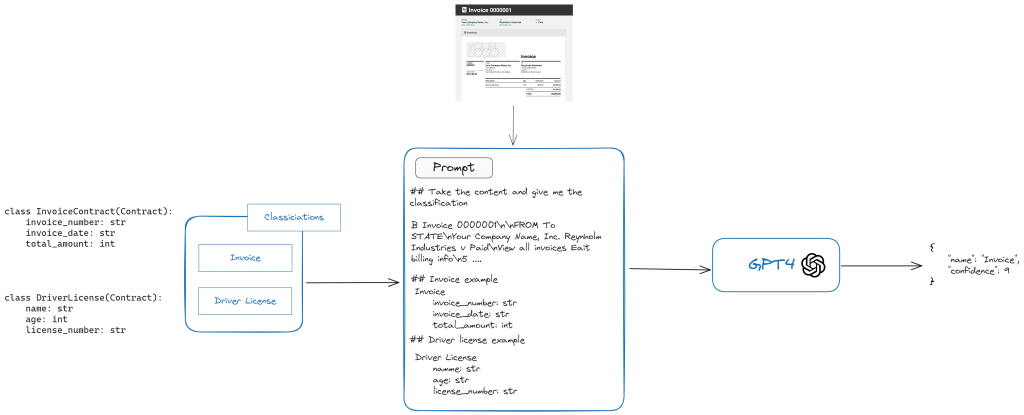
Comparación de Imágenes
La clasificación basada en imágenes puede ser crucial para documentos donde la estructura visual es importante. Aunque más costosa, esta técnica puede proporcionar resultados más precisos. Se recomienda una combinación de modelos como Azure phi-3 vision, Claude 3 y GPT-4 Vision para un stack de producción robusto.
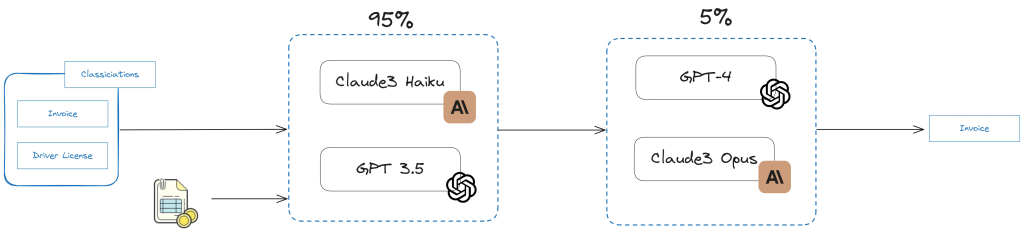
Mezcla de Modelos (MoM)
La Mezcla de Modelos es una estrategia para aumentar la confianza en la clasificación. Implica usar múltiples modelos en paralelo y combinar sus resultados. Las estrategias comunes incluyen:
- CONSENSO: Todos los modelos deben tener el mismo resultado.
- ORDEN SUPERIOR: Se elige el resultado con la puntuación más alta.
- CONSENSO CON UMBRAL: Una combinación de las dos anteriores con un umbral requerido.
Implementación con ExtractThinker
ExtractThinker es una biblioteca que simplifica la implementación de estas técnicas avanzadas de clasificación. Aquí hay un ejemplo de cómo usar ExtractThinker para clasificación básica:
classifications = [
Classification(
name="Driver License",
description="This is a driver license",
contract=DriverLicense, # opcional
),
Classification(
name="Invoice",
description="This is an invoice",
contract=InvoiceContract, # opcional
),
]
document_loader = DocumentLoaderTesseract(tesseract_path)
extractor = Extractor(document_loader)
extractor.load_llm("gpt-4o")
result = extractor.classify(INVOICE_FILE_PATH, classifications)Para implementar una Mezcla de Modelos, ExtractThinker proporciona la clase Process:
# Common classifications setup
classifications = [
Classification(
name="Driver License",
description="This is a driver license",
),
Classification(
name="Invoice",
description="This is an invoice",
),
]
tesseract_path = os.getenv("TESSERACT_PATH")
document_loader = DocumentLoaderTesseract(tesseract_path) # Can be any other
# Initialize the GPT-3.5 turbo extractor
gpt_3_5_turbo_extractor = Extractor(document_loader)
gpt_3_5_turbo_extractor.load_llm("gpt-3.5-turbo")
# Initialize the Claude 3 Haiku extractor
claude_3_haiku_extractor = Extractor(document_loader)
claude_3_haiku_extractor.load_llm("claude-3-haiku-20240307")
# Initialize the GPT-4 extractor
gpt_4_extractor = Extractor(document_loader)
gpt_4_extractor.load_llm("gpt-4o")
# Initialize the claude opus extractor
opus_extractor = Extractor(document_loader)
opus_extractor.load_llm("claude-3-opus-20240229")
process = Process()
# Create the process with the extractors
process = Process()
process.add_classify_extractor(
[
[gpt_3_5_turbo_extractor, claude_3_haiku_extractor],
[gpt_4_extractor, opus_extractor],
]
)
result = process.classify(INVOICE_FILE_PATH, classifications, strategy=ClassificationStrategy.ConsensusWithThreshold, threshold=9)El código es fácil de seguir. Se puede crear un proceso con múltiples extractores en cada paso, siguiendo un protocolo específico. En la imagen, el porcentaje representa la cantidad de carga que va a cada paso. Se puede desarrollar una estrategia que permita alcanzar un alto nivel de certeza (99%) al clasificar con LLM.
La clasificación de documentos con LLMs ofrece una flexibilidad y precisión sin precedentes. Las estrategias como el Mapeo de Tipos, la Comparación de Imágenes y la Mezcla de Modelos permiten alcanzar altos niveles de certeza en la clasificación. Herramientas como ExtractThinker simplifican la implementación de estas técnicas avanzadas, haciendo que la clasificación de documentos sea más eficiente y efectiva que nunca.
A medida que los LLMs continúan evolucionando, podemos esperar mejoras aún mayores en nuestra capacidad para clasificar documentos con alta precisión, abriendo nuevas posibilidades en el procesamiento y análisis de documentos.
Esto ha sido todo por ahora, espero que este artículo te sea de utilidad, si llegaste hasta aquí, déjame un comentario. Nos vemos en otra entrega de «Inteligencia Artificial Para Todos»
Average Rating