









LOTUS (Language Of Things for Unstructured and Structured data) es un framework revolucionario que está transformando la manera en que interactuamos con los datos. Este sistema innovador permite realizar consultas semánticas sobre tablas que contienen tanto datos estructurados como no estructurados, integrando directamente los Modelos de Lenguaje Grande (LLMs) en el pipeline de procesamiento de consultas de bases de datos.
La potencia de LOTUS radica en su capacidad para combinar lo mejor de dos mundos:
- La gestión de datos de alto rendimiento característica de las bases de datos tradicionales.
- El razonamiento avanzado y la comprensión del lenguaje natural propios de los modelos de IA más avanzados.
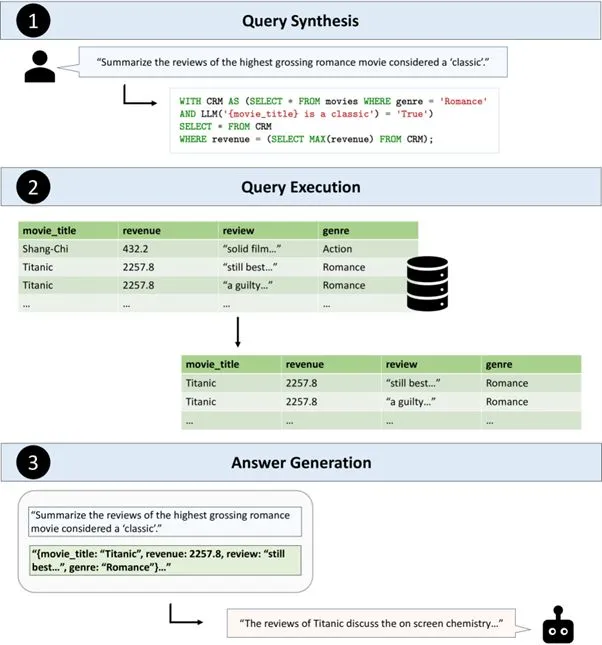
Esta combinación permite a los usuarios interactuar con sus datos de una manera más intuitiva y natural, al tiempo que mantiene la eficiencia y el rendimiento necesarios para el manejo de grandes volúmenes de información.
Consultas Semánticas
LOTUS permite a los usuarios realizar consultas semánticas, lo que significa que pueden interactuar con los datos utilizando lenguaje natural y conceptos de alto nivel. Esto contrasta con las consultas estructuradas tradicionales, que requieren un conocimiento preciso de la estructura de la base de datos y del lenguaje de consulta.
Integración de LLMs en Bases de Datos
Una característica distintiva de LOTUS es su capacidad para incorporar LLMs directamente en el proceso de consulta de la base de datos. Esto permite un procesamiento más inteligente y contextual de los datos, habilitando análisis más sofisticados y una mejor comprensión de la información almacenada.
Operadores Semánticos
LOTUS utiliza un conjunto de operadores semánticos para transformar dataframes de Pandas. Estos operadores son similares en concepto a los operadores relacionales en SQL, pero están diseñados específicamente para tareas de procesamiento de lenguaje natural:
Sem_Map: Aplica una transformación a cada fila del dataframe.Sem_Filter: Filtra las filas que cumplen con un predicado semántico.Sem_Agg: Agrega información a través de todas las filas.Sem_TopK: Ordena el dataframe según ciertos criterios.Sem_Join: Une dos dataframes basándose en un predicado semántico.Sem_Index: Crea un índice semántico sobre una columna.Sem_Search: Busca filas relevantes en el dataframe.
Configuración Inicial
Para comenzar a utilizar LOTUS, primero necesitamos configurar los modelos que utilizaremos. En este ejemplo, usaremos GPT-3.5-Turbo como modelo de lenguaje y E5 como modelo de incrustación:
import pandas as pd
import lotus
from lotus.models import E5Model, OpenAIModel
# Configurar modelos para LOTUS
lm = OpenAIModel(max_tokens=512)
rm = E5Model()
lotus.settings.configure(lm=lm, rm=rm)Ejemplo Práctico: Análisis de Cursos
Vamos a crear un dataframe con información sobre cursos y sus descripciones:
data = [
("Probabilidad y Procesos Aleatorios", "Se enfoca en cadenas de Markov y convergencia de procesos aleatorios. La carga de trabajo es bastante alta."),
("Aprendizaje Profundo", "Se centra en la teoría e implementación de redes neuronales. La carga de trabajo varía según el profesor, pero generalmente no es terrible."),
("Diseño Digital y Circuitos Integrados", "Se enfoca en la construcción de CPUs RISC-V en Verilog. Los estudiantes han dicho que la carga de trabajo es MUY alta."),
("Bases de Datos", "Se centra en la implementación de un SGBDR con temas de NoSQL al final. La mayoría de los estudiantes dicen que la carga de trabajo no es demasiado alta."),
]
df = pd.DataFrame(data, columns=["Nombre del Curso", "Descripción"])Filtrado Semántico y Agregación
Podemos usar LOTUS para filtrar cursos relacionados con el aprendizaje automático y luego generar un plan de estudio:
ml_df = df.sem_filter("{Descripción} indica que la clase es relevante para el aprendizaje automático.")
tips = ml_df.sem_agg(
"Dado cada {Nombre del Curso} y su {Descripción}, dame un plan de estudio para tener éxito en mis clases."
)._output[0]Top K Semántico
Para encontrar los cursos con mayor carga de trabajo:
top_2_hardest = df.sem_topk("¿Qué {Descripción} indica la carga de trabajo más alta?", 2)Unión Semántica
Podemos usar la unión semántica para encontrar cursos que nos ayuden a mejorar habilidades específicas:
skills_df = pd.DataFrame([("SQL"), ("Diseño de Chips")], columns=["Habilidad"])
classes_for_skills = skills_df.sem_join(
df, "Tomar {Nombre del Curso} me hará mejor en {Habilidad}"
)Indexación y Búsqueda Semántica
LOTUS permite crear índices semánticos y realizar búsquedas eficientes:
df = df.sem_index("Descripción", "directorio_indice")
top_conv_df = df.sem_search("Descripción", "Redes Neuronales Convolucionales", 1)Mapeo Semántico
Podemos usar el operador de mapeo semántico para generar temas de estudio adicionales para cada curso:
examples_df = pd.DataFrame(
[("Gráficos por Computadora", "Visión por Computadora"), ("Análisis Real", "Análisis Complejo")],
columns=["Nombre del Curso", "Respuesta"]
)
next_topics = df.sem_map(
"Dado {Nombre del Curso}, lista un tema que sería bueno explorar a continuación. \
Responde solo con el nombre del tema y nada más.",
examples=examples_df,
suffix="Próximos Temas"
)LOTUS representa un avance significativo en la integración de inteligencia artificial y gestión de bases de datos. Al permitir consultas semánticas sobre datos estructurados y no estructurados, y al integrar LLMs directamente en el proceso de consulta, LOTUS abre nuevas posibilidades para el análisis de datos y la toma de decisiones basada en información.
Enlace a la pagina de la documentación de LOTUS: https://lotus-ai.readthedocs.io/en/latest/
Tengo que decir que he hecho una prueba de LOTUS, he implementado un pequeño código de ejemplo en mi computador y me ha funcionado muy bien, los operadores semánticos van muy bien, en resumen lo que hice fue hacer una consulta a una tabla de una base de datos localmente y esos datos pasarlos a LOTUS luego puede hacer estas consultas semánticas y todo fue muy bien, en definitiva parece una buena idea de sus creadores y hay que seguir pues aun esta muy verde.
Esto ha sido todo por ahora, espero que este artículo te sea de utilidad, si llegaste hasta aquí, déjame un comentario. Nos vemos en otra entrega de «Inteligencia Artificial Para Todos»






{kind=link}